ISUCON13にチーム「ウー馬場ーイー222」で参加して最終スコアは 49,344 でした
TL;DR
2023年11月25日に開催されたISUCON13に参加しました。最終スコアは49,344でした。実装言語はGoです。今回のチーム名の由来は申し込み時のチームIDが222だったためです。
追記:30位でギリギリTOP30チームに入りました。やったね。
今回スコアが思ったほど奮わなかったのですが、敗因はN+1を甘く見ていたことだと思っています。MySQLのスロークエリーログ(トータル実行時間順)を見ているだけではだめで、実行回数をもっと重視する必要があるなと思いました。うん、そうだね。
今回はDNSが課題に組み込まれており、インフラエンジニア3人態勢の我々のチームの得意分野とする領域のはずだったのですが、DBのボトルネックを解消できずDNS周りに着手できませんでした。くやしー。
運営の皆様、ことしもよい問題をありがとうございました。来年こそはリベンジして上位入賞を目指したいと思います。がんばるぞー!!!
リポジトリは競技終了後に公開しました。
当日の様子は動画にしてYouTubeにアップしています。8時間ノー編集です。
体制
| あいこん | なまえ | やくわり | ペアプロ |
|---|---|---|---|
 |
matsuu | バリバリ実装する前衛 | ドライバー |
 |
netmarkjp | 司令塔+ベンチ実行+結果解析 | ナビゲーター |
 |
ishikawa84g | セキュリティ+情報官+動作確認 AppArmor、マニュアルや公式アナウンスの把握、ブラウザでの挙動確認 |
ナビゲーター |
3人はそれぞれリモートで、Discordでボイスチャット+画面共有で進めました。
使用したツールなど
| ツール | 用途 |
|---|---|
| sshrc | ssh接続時に手元の環境を持ち込むため |
| tmux | ターミナル分割など |
| vim | エディタ |
| top | リソース使用状況確認 |
| dstat | リソース使用状況確認 |
| MySQLTuner | MySQLパラメータ確認 |
| kataribe | アクセスログ解析 |
| go-mysql-query-digest | MySQLスロークエリー解析 |
昨年から代わり映えしないですね。 昨年はVimではなくNeovimを使ったんですが、Neovimを直前に整備していた際にLSP周りの挙動が怪しかったのでVimに切り替えました。
最終構成
| サーバ | 構成要素 | 備考 |
|---|---|---|
| 1台目 | nginx + app | appはGo実装 |
| 2台目 | mysql(isupipe) | |
| 3台目 | powerdns + mysql(isudns) |
スコア推移
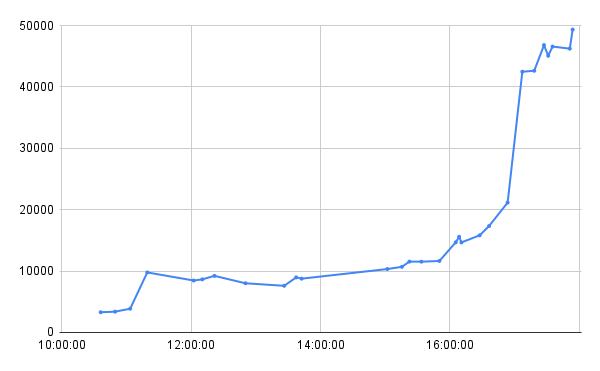
中盤で伸び悩んでますね。後半の大きな伸びは1台構成から3台構成に変更したためです。
やったこと
「時間 スコア 概要」 でまとめていきます。
10:49 3386 初回ベンチ
一通りログ解析などができる体制をセットアップした後での初回ベンチです。 各種スロークエリーログ出力を仕込んだうえで、MySQLのバイナリログを無効化してます。
# /etc/mysql/mysql.conf.d/mysqld.cnf disable-log-bin
11:19 7,888 インデックス追加など
取り急ぎMySQLが高負荷だったのでインデックスの追加などをしました。
- Goで定番の設定
interpolateParams=trueを追加 - Goのアプリログ出力を抑制
- インデックス追加
use isupipe; ALTER TABLE icons ADD INDEX (user_id); ALTER TABLE themes ADD INDEX (user_id); ALTER TABLE livestreams ADD INDEX (user_id); ALTER TABLE reservation_slots ADD INDEX (start_at, end_at); ALTER TABLE livestream_tags ADD INDEX (livestream_id); ALTER TABLE livecomments ADD INDEX (livestream_id); ALTER TABLE reactions ADD INDEX (livestream_id); use isudns; ALTER TABLE records ADD INDEX (name);
12:02 8,460 NGワード該当チェックをアプリ側で実施するよう変更
インデックス追加の結果、MySQLのスロークエリーの上位にきているのが以下のようなSQLでした。
DELETE FROM livecomments WHERE id = 66 AND livestream_id = 7526 AND (SELECT COUNT(*) FROM (SELECT 'あなたの私物や日常の詳細を知りたいな〜。どこで買い物してるのかな?教えて!' AS text) AS texts INNER JOIN (SELECT CONCAT('%', '生体情報解析', '%') AS pattern) AS patterns ON texts.text LIKE patterns.pattern) >= 1\G
何やらややこしい実装になっているものの、コメントにNGワードが含まれているかをチェックしてるだけだったので、まずはアプリ側でチェックを行うよう変更しました。スコアは下がったものの、クエリーは高速になったのでとりあえず良しとしました。
12:21 9,220 NGワードの周りのN+1を解消
NGワードが追加されるたびに過去のNGワードも再度コメントチェックをしているのは無駄と判断し、追加されたNGワードについてのみ削除するよう実装変更しました。
if _, err := tx.ExecContext(ctx, "DELETE FROM livecomments WHERE livestream_id = ? AND comment LIKE ?", livestreamID, fmt.Sprintf("%%%s%%", req.NGWord)); err != nil { return echo.NewHTTPError(http.StatusInternalServerError, "failed to delete old livecomments that hit spams: "+err.Error()) }
12:33 - 昼休憩
12:50 8,012 DNSレコードにTTLを設定
各種DNSレコードにTTLを設定すればリクエスト頻度が下がるのではないか?と考えてTTLを設定しました。 しかしスコアは改善しませんでした。悪影響もなさそうなのでとりあえず変更したまま進めます。
13:37 8,968 Deadlock対策
iconsテーブルで発生しているDeadlockのエラーを解消するため、DELETEしてからINSERTしている処理をREPLACEに置き換えました。また、次の布石としてiconsテーブルにカラムを追加してiconのハッシュ値を格納しています。
15:01 10,331 いろいろ変更
この時間までは運営側のデプロイが繰り返し行われておりベンチマークを回せなかったのでまとめていろいろ改修しています。
- PowerDNSの負荷抑制のためログ出力を抑制
- アプリ側のDBへの最大同時接続数を10から128に引き上げ
- getUserStatisticsにおけるランク算出のN+1を解消
If-None-Matchリクエストヘッダーに対して304応答を返すよう実装(できてない)
15:15 10,687 tagsのN+1を解消
まだまだMySQLの負荷がボトルネックなのでスロークエリーログの対処をしています。tagsでN+1になっていた処理を解消しました。
15:22 11,540 iconの304応答を実装
If-None-Match リクエストヘッダーは " で括られて届いていることを考慮できてなかったので、これに対処しました。
16:10 14,666 スコアをテーブルに保存
getUserStatisticsのランク算出がスロークエリーの上位だったため、事後集計を行うのではなくreactionとtipを投げた際にスコアを積算するようにしました。scoresテーブルを追加しています。 初期状態でも正しいランクを出力できるようinitialize時にscoresテーブルのレコードも追加するように対処しています。
CREATE TABLE `scores` ( `user_id` BIGINT NOT NULL PRIMARY KEY, `name` VARCHAR(255) NOT NULL, `score` INT NOT NULL, INDEX(score, name) ) ENGINE=InnoDB CHARACTER SET utf8mb4 COLLATE utf8mb4_bin; INSERT INTO scores (user_id, name, score) SELECT u.id, u.name AS name, (SELECT count(*) from livestreams l inner join reactions r on r.livestream_id = l.id WHERE u.id = l.user_id) + (SELECT IFNULL(SUM(l2.tip), 0) FROM livestreams l INNER JOIN livecomments l2 ON l2.livestream_id = l.id WHERE u.id = l.user_id) AS score FROM users u;
16:36 17,337 iconのハッシュ値をアプリ側でキャッシュ
iconのハッシュ値をDBに格納したことでDBへの問い合わせ頻度が多くなっていたため、ハッシュ値はアプリ側でキャッシュするようにしました。アプリ側のキャッシュは sync.Map を利用しています。
長年のISUCON経験から、アプリが再起動した場合やinitializeが実行された場合の対処もぬかりなく実施しています。
16:53 21,153 themeをアプリ側でキャッシュ
ハッシュ値と同様にthemeを問い合わせるクエリーを削減すべくthemeをアプリ側でキャッシュしました。こちらも sync.Map で実装しています。
17:07 42,477 MySQLを2台目サーバに移設
まだこのタイミングでもMySQLがボトルネックだったのですが、残り1時間ということもあり複数台構成へと変更し始めました。まずはMySQLを2台目サーバに変更しています。
17:18 42,631 PowerDNSのMySQLを3台目サーバに移設
PowerDNS全体を切り替えることは最初つまづいたので、まずはPowerDNSは1台目サーバで稼働したまま、PowerDNSのバックエンドMySQLだけ3台目サーバに切り替えました。
17:27 46,797 PowerDNSを3台目サーバで稼働するように変更
PowerDNSのレコード初期化とレコード登録の仕組みを丹念に調べながら、PowerDNSを3台目サーバで稼働するように変更しました。レコード初期化とレコード登録は強引ではあるもののSSH経由で実行しています。
-if out, err := exec.Command("pdnsutil", "add-record", "u.isucon.dev", req.Name, "A", "60", powerDNSSubdomainAddress).CombinedOutput(); err != nil { +if out, err := exec.Command("ssh", "192.168.0.13", "pdnsutil", "add-record", "u.isucon.dev", req.Name, "A", "60", powerDNSSubdomainAddress).CombinedOutput(); err != nil {
-bash ../pdns/init_zone.sh +ssh 192.168.0.13 bash webapp/pdns/init_zone.sh
17:48 - PowerDNSのバックエンドをLMDBに切り替えようとするも断念
PowerDNSをMySQLからLMDBに切り替えれば高速になるとの情報から、切り替えを試みるものの時間が足りず断念しました。あとちょっとだったけど時間が足りなかった。くやしい。
17:53 49344 スローログなどを無効にして最終ベンチ
スロークエリーログやアクセスログの出力を抑制して最終ベンチを回して最高スコアをたたき出してフィニッシュしました。 その他、再起動エラー対策のsystemd設定変更も併せて実施しています。
SQL50本ノックをSQLite3 Fiddleで試す
Software Design「データベース速攻入門」に「SQL50本ノック」が掲載されました - LIVESENSE ENGINEER BLOG
最近では、postgres-wasmなど、WebブラウザでDBを動かせるようになってきており、もう少しすれば、WebAssemblyを使って、ブラウザですぐにノックを始められるようになるかもしれません。もしも、また何年か後に記事を更新する機会があれば、試してみたいですね。
Web上からすぐに試せるpostgres-wasmはPagilaのデータを持っていくことが現時点で出来なさそうだったものの、SQLite3 WebAssemblyはSQLiteのデータを持っていけました。SQL50本ノックを気軽に試せそうです。
手順1 sakila-sqlite3をダウンロード
まずgithubからsakila-sqlite3をダウンロードします。
github.com
直リンクはこちらです。 sakila_master.db がダウンロードできればok。
手順2 SQLite3 Fiddleでsakila-sqlite3をロード
SQLite3 Fiddleにアクセスします。画面下の Load DB... で先ほどダウンロードした sakila_master.db を選択して読み込みます。
手順3 細かい設定変更を行う(オプション)
画面下のOptionは以下がオススメです。
Auto-scroll outputは offAuto-clear outputは on
手順4 はじめよう
あとは書籍を見ながらSQL50本ノックにチャレンジ! gihyo.jp
SQLiteでの注意事項
- SQLiteのデフォルト設定ではSELECTした結果にカラム名が表示されません。
.headers onを設定すればカラム名を表示することができます。 - SQLiteではデフォルトだと列揃えがされません。列を揃えたい方は
.mode columnを設定しましょう。 - SQLite3 Fiddleではレコード数が多いと表示にかなり時間がかかります。ノック01でいきなり待たされます。
Auto-scroll outputをoffにするとやや早いです - 書籍ではPostgreSQLのため最後に出力された行数が表示されてますが、SQLiteの場合は行数が表示されません。必要に応じて
SELECT COUNT(*) FROM ...で行数を確認してください - 元データの差異が理由と思いますが、paymentテーブルの
payment_idの値が異なるようですので適宜読み替えてください - 書籍ではNULLのデータが空欄になっていますが、SQLite Fiddleでは
NULLと表示されます - rentalテーブルの
return_dateなどTIMESTAMPの表示形式が書籍と異なるので適宜読み替えてください - SQLiteとPostgreSQLでROUND関数の仕様が異なるため適宜書き換えが必要です。CAST関数も必要になるでしょう
- CONCATの代わりに
||演算子が使えます - information_schemaはないので代わりに
.schemaを駆使しましょう - SQLiteの正規表現はREGEXPが使用できます
- SQLiteで浮動小数点の計算は誤差が発生する可能性があります(ノック28)
- TIMESTAMPから日付を取り出すのはCASTではなくDATE関数が使えます
- 月別はEXTRACTではなくstrftime関数が使えます
- payment_p2022_XXテーブルは存在しないので適宜作成するか読み替えましょう
ISUCON12予選の様子(画面操作)をYouTubeに公開しました
今回のISUCONで初の試みとして、画面操作を録画したのでYouTubeに公開しました。自分の肉声も含まれています。
映像は8時間ノーカットです。音声は乗せられない会話、クシャミ、昼食中の啜る音などだけ除去しています。
チームメンバーと会話しながら進めたものの、プライバシーを配慮してあえて自分の声しか入れてません。相槌を打っているだけのシーンもあるので内容はすべて把握できないかもしれません。
画面収録はmacOS標準機能を使いました。動画編集はmacOS標準のiMovieを使っています。
ちゃんとした動画をYouTubeにアップロードしたのも初めてだったので不手際があれば教えてください。
得られた教訓
- 黒地に白文字は動画にすると読みづらいので白地に黒文字にすべきだった
- 更新があまりないターミナルの画面(1920x1080)を8時間録画すると約20GBの動画ファイルになる
- 音声を編集するためにiMovieを初めて使ったが、レンダリングファイルで500GBのストレージ容量がすぐに埋まってしまうのでこまめに消す必要がある
- 8時間をまるごとYouTubeにアップロードするとYouTube上の動画エディタが長過ぎて使えず、字幕編集機能もメモリ不足でエラーになるので複数の動画に分けるべき
- 自分の滑舌が悪いこともありYouTubeが自動でつけてくれる字幕はお粗末、かつ8時間もあると膨大な量で修正するのは心が折れる(折れた)
- YouTubeには動画チャプター機能があるが、タイムラインを書いたものの反映されなかったので悲しい
- サムネイルは重要なんだろうなと思った
ISUCON12本選でチーム シン・ウー馬場ーイー2 として参加し、12位でした
TL;DR
ISUCON12本選の結果は12位となりました。最終スコアは106,254でした。
順位が振るわなかった理由は、以下の3点と自分では考えています。
- デッドロックの解消に時間を使い過ぎてしまった
- 複数台サーバの利用方法を最終盤まで後回しにした
- 5台もあるので分割方法を早々に考えるべきであった
- 結局2台しか活用できなかった
- シャーディングの発想がでてこなかった
- シャーディングを自分で実装した経験がなかった
- 仮に思いついたとしても作業コストが想定できなかった
デッドロックは延長戦で解消する方法をある程度確立したので、今後のISUCONに活かしたいと思います。 シャーディングは1度でも経験しておけば着手できたのではないかと思いますが、たとえ発想できたとしても実装経験がなくどの程度の難易度かを見積ることができなかったと思います。 本選終了後の延長戦で実際にシャーディングを試みたところ、想像していたよりは簡単に実装できたので、やはり1度でも経験というのは大事なのだなと噛み締めた次第です。
リポジトリは競技終了後に公開しました。
mainブランチ: 本選でやったこと github.com
延長戦ブランチ: 9/4までの延長戦でやったこと github.com
| シーン | スコア | 備考 |
|---|---|---|
| 本選初回スコア | 534 | スロークエリー出力など含む |
| 本選最高スコア | 113,637 | |
| 本選最終スコア | 106,254 | 運営計測 |
| 延長戦最高スコア | 391,711 |
ISUCON12本選の延長戦、あえて他チームの解法を見ずに自力で解いてたけど、このあたりが限界です。対戦ありがとうございました。
— matsuu(シン・ウー馬場ーイー2) (@matsuu) 2022年9月3日
本選の内容はmainブランチ、延長戦は延長戦ブランチに入れて公開。https://t.co/ISPgLNzcLO pic.twitter.com/E6LrcD1GMQ
体制
| あいこん | なまえ | やくわり | ペアプロ |
|---|---|---|---|
| |
matsuu | バリバリ実装する前衛 | ドライバー |
| |
netmarkjp | 司令塔+ベンチ実行+結果解析 | ナビゲーター |
| |
ishikawa84g | セキュリティ+情報官+動作確認 AppArmor、マニュアルや公式アナウンスの把握、ブラウザでの挙動確認 |
ナビゲーター |
3人はそれぞれリモートで、Discordでビデオチャットをしつつ画面共有してました。
使用したツールなど
| ツール | 用途 |
|---|---|
| sshrc | ssh接続時に手元の環境を持ち込むため |
| zellij NEW! | tmux代替 |
| tmux | ターミナル分割など |
| neovim NEW! | エディタ |
| top | リソース使用状況確認 |
| dstat | リソース使用状況確認 |
| MySQLTuner | MySQLパラメータ確認 |
| kataribe | アクセスログ解析 |
| go-mysql-query-digest NEW! | MySQLスロークエリー解析 |
予選では使ってなかったzellijを今回導入しましたが、本選中に不具合に遭遇したので断念してtmuxに切り替えました。
最終構成
| サーバ | 構成要素 | 備考 |
|---|---|---|
| 1台目 | nginx + app | appはGo実装 |
| 2台目 | mysql | |
| 3台目 | 利用せず | |
| 4台目 | 利用せず | |
| 5台目 | 利用せず |
今回は最後までDBの負荷が高い状態を改善できませんでした。トランザクションで処理するテーブル群をかたまりとして複数DBに分けようとしたのですが、関連するテーブルが多い上に負荷をうまく分散できる気がしなかったので、テーブル単位のDBサーバ分割は難しいと判断して結局活用できませんでした。
予選ではRustで始めて途中からGoに切り替えましたが、本選は最初からGoで進めました。来年こそは別言語で出たいと思います。
スコア推移
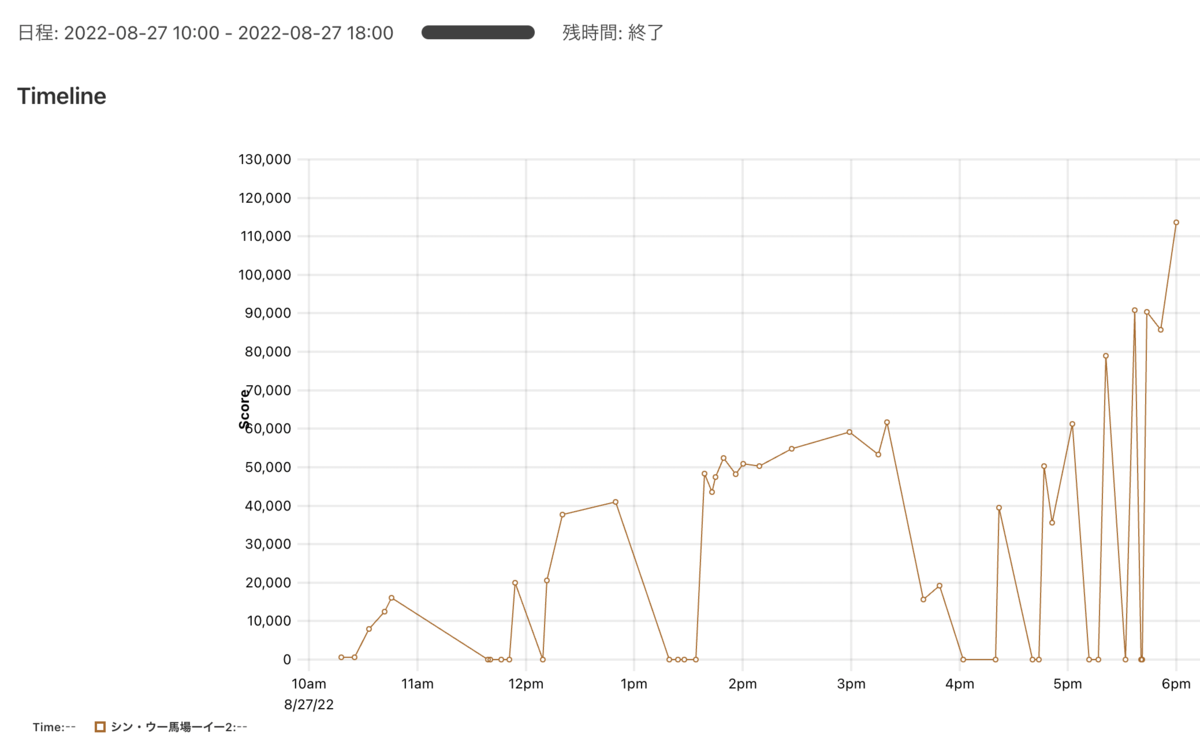
後半伸び悩んでいるのはデッドロックに苦しめられた期間です。
やったこと
「時間 スコア 概要」 でまとめていきます。
10:25 534 初回ベンチ
一通りログ解析などができる体制をセットアップした後での初回ベンチです。 スロークエリー出力を仕込んだ上でのベンチ実行なので、何もせずにベンチを仕掛けるよりは遅くなっています。
10:34 7,888 user_present_all_received_historyにインデックス追加
topの出力を見る限りmysqldのCPU負荷が支配的だったので、まずはMySQLのスロークエリーから遅いクエリーを抽出してインデックスを追加しました。
/* 全員プレゼント履歴テーブル */
CREATE TABLE `user_present_all_received_history` (
`id` bigint NOT NULL,
`user_id` bigint NOT NULL comment '受けとったユーザID',
`present_all_id` bigint NOT NULL comment '全員プレゼントマスタのID',
`received_at` bigint NOT NULL comment '受け取った日時',
`created_at` bigint NOT NULL,
`updated_at`bigint NOT NULL,
`deleted_at` bigint default NULL,
+ INDEX (user_id, present_all_id),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
ここで暫定1位です。
10:42 12,503 MySQLチューニング
インデックス追加の結果をtopとdatatで確認したところ、cpu usrの割合が下がったものの、iowaitの比率が上がっていることを確認しました。そこでバイナリログなどの出力が多いと考えてMySQLをチューニングしました。
MySQLのバージョンは予選では8.0.29、本選は8.0.30でした。このバージョン差異は我々のチームにとっては影響大でした。詳しくは以下をご参照ください。
予選の復習中にこの差異は確認済だったので、秘伝のタレも合わせて修正しています。
/etc/mysql/mysql.conf.d/mysqld.cnf
disable-log-bin innodb_buffer_pool_size=1G innodb_doublewrite = 0 innodb_flush_log_at_trx_commit = 0 innodb_flush_log_at_timeout = 3 innodb_log_group_home_dir = /dev/shm innodb_redo_log_capacity = 128M
/etc/tmpfiles.d/mysqld_redo.conf
d /dev/shm/#innodb_redo 750 mysql mysql
/etc/apparmor.d/usr.sbin.mysqld
/etc/ssl/openssl.cnf r, # Site-specific additions and overrides. See local/README for details. #include <local/usr.sbin.mysqld> + + /dev/shm/ r, + /dev/shm/** rwk, }
11:05 - 当日マニュアル読み合わせ
ここでishikawa84gが要点をまとめた当日マニュアルの読み合わせを行っています。要点だけを把握して共有しているのでとても効率が良い方針だと思っています。
11:54 20,011 generateIDをAUTO_INCREMENTに変更
MySQLのチューニングによってcpu iowaitの割合は下がり、再びcpu usrの割合が高くなりました。MySQLのスロークエリーは以下のクエリーが支配的であることを確認。
UPDATE id_generator SET id=LAST_INSERT_ID(id+1)\G
予選と実装方法は異なるものの、似たようなテーブルまたぎのID生成です。
// generateID uniqueなIDを生成する func (h *Handler) generateID() (int64, error) { var updateErr error for i := 0; i < 100; i++ { res, err := h.DB.Exec("UPDATE id_generator SET id=LAST_INSERT_ID(id+1)") if err != nil { if merr, ok := err.(*mysql.MySQLError); ok && merr.Number == 1213 { updateErr = err continue } return 0, err } id, err := res.LastInsertId() if err != nil { return 0, err } return id, nil } return 0, fmt.Errorf("failed to generate id: %w", updateErr) }
予選ではidが varchar(255) だったのでuuidに変更しましたが、今回のidは bigint だったので AUTO_INCREMENT 実装に取り急ぎ変更しました。
ただ、テーブル数が多くINSERTクエリーからidを取り除く対応にやや時間がかかっています。
12:11 - user_presentsテーブルのN+1を解消
スコアの記録は失念しましたが、ほとんど増えてなかったと思います。
引き続きMySQLのcpu usrが支配的なのでMySQLスロークエリーを確認します。上位はuser_presentsテーブルに対する更新だったのでここに注目し、user_presentsに対してN+1でUPDATEしている部分を外だししています。
@@ -1287,6 +1287,13 @@ func (h *Handler) receivePresent(c echo.Context) error { } defer tx.Rollback() //nolint:errcheck + query = "UPDATE user_presents SET deleted_at=?, updated_at=? WHERE id IN (?) AND deleted_at IS NULL" + query, params, err = sqlx.In(query, requestAt, requestAt, req.PresentIDs) + _, err = tx.Exec(query, params...) + if err != nil { + return errorResponse(c, http.StatusInternalServerError, err) + } + // 配布処理 for i := range obtainPresent { if obtainPresent[i].DeletedAt != nil { @@ -1296,11 +1303,6 @@ func (h *Handler) receivePresent(c echo.Context) error { obtainPresent[i].UpdatedAt = requestAt obtainPresent[i].DeletedAt = &requestAt v := obtainPresent[i] - query = "UPDATE user_presents SET deleted_at=?, updated_at=? WHERE id=?" - _, err := tx.Exec(query, requestAt, requestAt, v.ID) - if err != nil { - return errorResponse(c, http.StatusInternalServerError, err) - } _, _, _, err = h.obtainItem(tx, v.UserID, v.ItemID, v.ItemType, int64(v.Amount), requestAt) if err != nil {
12:20 37,716 nginxチューニング
nginxのerror_logを確認したところToo many open filesのエラーが発生していることを確認したので、ここでnginxをチューニングしています。
--- a/etc/nginx/nginx.conf +++ b/etc/nginx/nginx.conf @@ -1,12 +1,13 @@ user www-data; worker_processes auto; +worker_rlimit_nofile 65536; -error_log /var/log/nginx/error.log warn; +error_log /var/log/nginx/error.log notice; pid /run/nginx.pid; events { - worker_connections 1024; + worker_connections 2048; } @@ -24,6 +25,7 @@ http { #tcp_nopush on; keepalive_timeout 65; + keepalive_requests 100000000; #gzip on; --- a/etc/nginx/sites-available/isuconquest.conf +++ b/etc/nginx/sites-available/isuconquest.conf @@ -1,27 +1,42 @@ +upstream app { + server localhost:8080; + keepalive 128; + keepalive_requests 10000000; +} server { root /home/isucon/isucon12-final/webapp/public; listen 80 default_server; listen [::]:80 default_server; location /user { - proxy_pass http://localhost:8080; + proxy_pass http://app; + proxy_http_version 1.1; + proxy_set_header Connection ""; } location /admin{ - proxy_pass http://localhost:8080; + proxy_pass http://app; + proxy_http_version 1.1; + proxy_set_header Connection ""; } location /login { - proxy_pass http://localhost:8080; + proxy_pass http://app; + proxy_http_version 1.1; + proxy_set_header Connection ""; } location /health { - proxy_pass http://localhost:8080; + proxy_pass http://app; + proxy_http_version 1.1; + proxy_set_header Connection ""; } location /initialize { proxy_read_timeout 600; - proxy_pass http://localhost:8080; + proxy_pass http://app; + proxy_http_version 1.1; + proxy_set_header Connection ""; } location / {
12:38 - 昼食タイム
12:38頃まで昼食とってます。もぐもぐ
12:50 41,000 複数テーブルにインデックス追加
Too many open filesが解消した結果、再びmysqldのcpu usrが多いのでスロークエリーを確認してインデックスを追加しました。
--- a/home/isucon/webapp/sql/3_schema_exclude_user_presents.sql +++ b/home/isucon/webapp/sql/3_schema_exclude_user_presents.sql @@ -178,7 +178,7 @@ CREATE TABLE `user_items` ( `updated_at`bigint NOT NULL, `deleted_at` bigint default NULL, PRIMARY KEY (`id`), - INDEX userid_idx (`user_id`) + INDEX userid_idx (`user_id`, `item_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; ALTER TABLE user_items AUTO_INCREMENT=100000000001; @@ -234,7 +234,8 @@ CREATE TABLE `user_sessions` ( `expired_at` bigint NOT NULL, `deleted_at` bigint default NULL, PRIMARY KEY (`id`), - UNIQUE uniq_session_id (`user_id`, `session_id`, `deleted_at`) + INDEX (`session_id`), + UNIQUE uniq_session_id (`user_id`, `deleted_at`, `session_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; ALTER TABLE user_sessions AUTO_INCREMENT=100000000001; @@ -249,7 +250,8 @@ CREATE TABLE `user_one_time_tokens` ( `expired_at` bigint NOT NULL, `deleted_at` bigint default NULL, PRIMARY KEY (`id`), - UNIQUE uniq_token (`user_id`, `token`, `deleted_at`) + INDEX (`token`), + UNIQUE uniq_token (`user_id`, `deleted_at`, `token`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; ALTER TABLE user_one_time_tokens AUTO_INCREMENT=100000000001; @@ -263,7 +265,8 @@ CREATE TABLE `admin_sessions` ( `expired_at` bigint NOT NULL, `deleted_at` bigint default NULL, PRIMARY KEY (`id`), - UNIQUE uniq_admin_session_id (`user_id`, `session_id`, `deleted_at`) + INDEX (`session_id`), + UNIQUE uniq_admin_session_id (`user_id`, `deleted_at`, `session_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; ALTER TABLE admin_sessions AUTO_INCREMENT=100000000001;
13:39 48,289 プレゼント付与処理のN+1解消
引き続きmysqldのcpu usrが高く、上位のクエリーは実行回数が多い状況を確認したので、上位のものから順番にN+1を解消する方向で進めています。このあたりから大掛かりなアプリ改修になっています。
13:50 52,453 JSONの生成ライブラリをgoccy/go-jsonに変更
すべての応答がjsonになっているので高速なライブラリである goccy/go-json に差し替えました。
14:01 50,961 もう一箇所のuser_presentsのINSERTをbulk insertに
引き続きN+1を解消させています。しかしこのあたりの改修でデッドロックが発生し始めています。
スコアは下がりましたが方向性は間違っていないと判断して突き進みますが、これが地獄の始まりでした。
14:10 50,239 user_presentsテーブルのインデックスを調整
スロークエリーの上位に来ているuser_presentsテーブルのインデックス周りを調整します。
--- a/home/isucon/webapp/sql/setup/1_schema.sql +++ b/home/isucon/webapp/sql/setup/1_schema.sql @@ -135,7 +135,7 @@ CREATE TABLE `user_present_all_received_history` ( ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; CREATE TABLE `user_presents` ( - `id` bigint NOT NULL, + `id` bigint NOT NULL AUTO_INCREMENT, `user_id` bigint NOT NULL comment 'ユーザID', `sent_at` bigint NOT NULL comment 'プレゼント送付日時', `item_type` int(1) NOT NULL comment 'アイテム種別', @@ -146,7 +146,7 @@ CREATE TABLE `user_presents` ( `updated_at`bigint NOT NULL, `deleted_at` bigint default NULL, PRIMARY KEY (`id`), - INDEX userid_idx (`user_id`) + INDEX user_id (`user_id`, `deleted_at`, `created_at` DESC) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
14:27 54,744 obtainItemでSELECTしてからUPDATEしているものをUPDATE一発に変更
N+1の中でSELECT→UPDATEとしているのをUPDATEで一発更新にしました。
--- a/home/isucon/webapp/go/main.go +++ b/home/isucon/webapp/go/main.go @@ -497,18 +497,8 @@ func (h *Handler) obtainItem(tx *sqlx.Tx, userID, itemID int64, itemType int, ob switch itemType { case 1: // coin - user := new(User) - query := "SELECT * FROM users WHERE id=?" - if err := tx.Get(user, query, userID); err != nil { - if err == sql.ErrNoRows { - return nil, nil, nil, ErrUserNotFound - } - return nil, nil, nil, err - } - - query = "UPDATE users SET isu_coin=? WHERE id=?" - totalCoin := user.IsuCoin + obtainAmount - if _, err := tx.Exec(query, totalCoin, user.ID); err != nil { + query := "UPDATE users SET isu_coin=isu_coin+? WHERE id=?" + if _, err := tx.Exec(query, obtainAmount, userID); err != nil { return nil, nil, nil, err } obtainCoins = append(obtainCoins, obtainAmount)
15:00 59,147 obtainItem関数をreceivePresentへinline化
kataribe で確認するとトータルの応答時間が長いのは receivePresent でした。この中でN+1で呼ばれているobtainItemを最終的に解消すべく、まずはobtainItem関数をinline化して不要な処理は取り除いています。
https://github.com/matsuu/isucon12f/commit/ad0fe3d6078be542f96373fa4a2bc995b4c09282
15:15 53,345 receivePresentのN+1を一部解消
inline化したobtainItem関数の処理をN+1から外して一括処理させることで解消を目指しました。 しかしデッドロックが増えて事態はさらにひどくなりはじめました。
15:20 61,679 goからDBへの接続時のアイドルコネクション周りを調整
クエリー実行回数が多いことからDB接続周りをチューニングしています。
--- a/home/isucon/webapp/go/main.go +++ b/home/isucon/webapp/go/main.go @@ -125,6 +125,8 @@ func connectDB(batch bool) (*sqlx.DB, error) { if err != nil { return nil, err } + dbx.SetMaxOpenConns(140) + dbx.SetMaxIdleConns(140) return dbx, nil }
16:47 50,216 テーブルの更新順を並び替えてみたがデッドロック解消せず
このあたりは時間をかけてデッドロックの原因を探っており、複数のトランザクションのテーブル更新順を入れ替えるなどしていました。一通り対応したものの本選中はデッドロックは解消しません。うんとこしょ、どっこいしょ
16:51 35,649 SQLにFOR UPDATEをつけたがデッドロック解消せず
SELECT時にFOR UPDATEをつけてテーブルロックの順番を揃えようとしましたが、それでもデッドロックは解消しません。難しいですね。
17:08 61,197 14:27時点までrevert
辛い決断をしました。15:20のDB接続周りを除き、14:27時点までrevertしています。
17:21 78,910 dbを2台目サーバに移動
残り時間もなくなってきているので、まずDBを2台目サーバに移動しました。それによりスコアは伸びましたが3台目以降の使い道は決められませんでした。
17:37 85,692 セッションのdeleted_at更新をレコード削除に変更
コミットメッセージがやや間違ってますが、user_sessionsの論理削除を物理削除に変更しました。少しでもスコアを伸ばそうという涙ぐましい努力です。
17:59 113,637 ログ出力無効化やappのnofile調整など
最後にスロークエリーログやアクセスログを停止してLimitNOFILEを定義してフィニッシュです。お疲れ様でした。
延長戦 391,711 いろいろ
本選参加者はそのまま同じ環境を使って9/4まで延長戦ができたので参戦しました。 シャーディングやセッションのRedis化などを諸々実装しました。詳しくは下記コミットをご確認ください。
ISUCON12予選にシン・ウー馬場ーイー2として参加し、2位で予選突破しました
TL;DR
ISUCON12予選にシン・ウー馬場ーイー2 として出場しました。 結果、予選2位で本選出場をきめました。やったね。 最終スコアは75800、予選中のベストスコアは76525でした。本選もがんばるぞ!
毎年素晴らしいコンテストを開催してくださる運営様には感謝しかありません。本当にありがとうございます!!1
体制
| あいこん | なまえ | やくわり | ペアプロ |
|---|---|---|---|
| |
matsuu | バリバリ実装する前衛 | ドライバー |
| |
netmarkjp | 司令塔+ベンチ実行+結果解析 | ナビゲーター |
| |
ishikawa84g | セキュリティ+情報官+動作確認 AppArmor、マニュアルや公式アナウンスの把握、ブラウザでの挙動確認 |
ナビゲーター |
今年も3人が別々の場所からリモート参加です。 コミュニケーションはDiscordを使ってます。3人それぞれの画面を共有しながら音声チャットつなぎっぱなしです。
手元の環境
どうでもいい話ですが物理スペックです。
| 項目 | 品名 |
|---|---|
| メイン機 | Mac mini(M1, 2020) NEW! + モニター2台 |
| キーボード | Magic Keyboard NEW! |
| マウス | logicool ELGO M575 NEW! |
| イヤホン | Shokz Aeropex |
| マイク | marantz MPM-1000U |
| 椅子 | Ergohuman Basic NEW! |
値上げ発表後にヨドバシで駆け込み購入したMac miniです。購入費用はISUCONの優勝賞金の前借りです(皮算用)。
使用したツールなど
| ツール | 用途 |
|---|---|
| sshrc | ssh接続時に手元の環境を持ち込むため |
| tmux | ターミナル分割など |
| neovim NEW! | エディタ |
| top | リソース使用状況確認 |
| dstat | リソース使用状況確認 |
| MySQLTuner | MySQLパラメータ確認 |
| kataribe | アクセスログ解析 |
| go-mysql-query-digest NEW! | MySQLスロークエリー解析 |
今回vimからneovimに乗り換えました。設定はこちら。 pt-query-digestが解析に時間がかかることに業を煮やして拙作go-mysql-query-digestを導入しました。
方針
- サーバ上で直接neovimでソースコードを変更するスタイル
- 手元での再現環境構築や外部からのデプロイは行わない
sshrcで環境がかぶらないようにしてメンバーごとにnvim/ssh環境を分離
- 実装言語はまずはRustを選択、問題が出たらGoを選択
- 負荷テスト中は
topとdstat -tlampを目視確認 - 負荷テスト後にアクセス解析
/でgit init
リポジトリは競技終了後に公開しました。 github.com
最終構成
当初は1台目のみを使い、残り1時間のタイミングで複数サーバを使うように構成変更しました。
| サーバ | 構成要素 | 備考 |
|---|---|---|
| 1台目 | nginx + app(go) | nginxは1台目と3台目のappにround-robin |
| 2台目 | MySQL | 初期実装のままバージョン変更なし |
| 3台目 | app(go) | 1台目のapp(go)と同じ実装 |
ちなみに昨年こんなこと書いており
— matsuu(シン・ウー馬場ーイー2) (@matsuu) 2021年10月7日当初はRustで進めていたんですが、競技中にRustからGoに切り替えました。😥
スコア推移
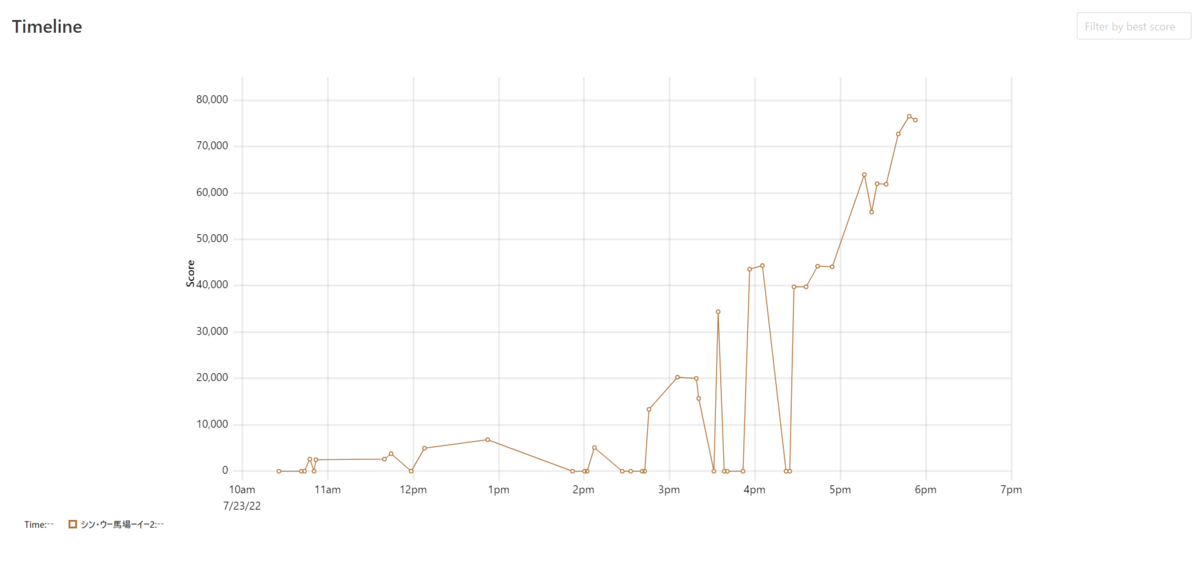
大きな飛躍はなく順当にボトルネックを潰したようなスコア推移になりました。
ベンチマーク履歴
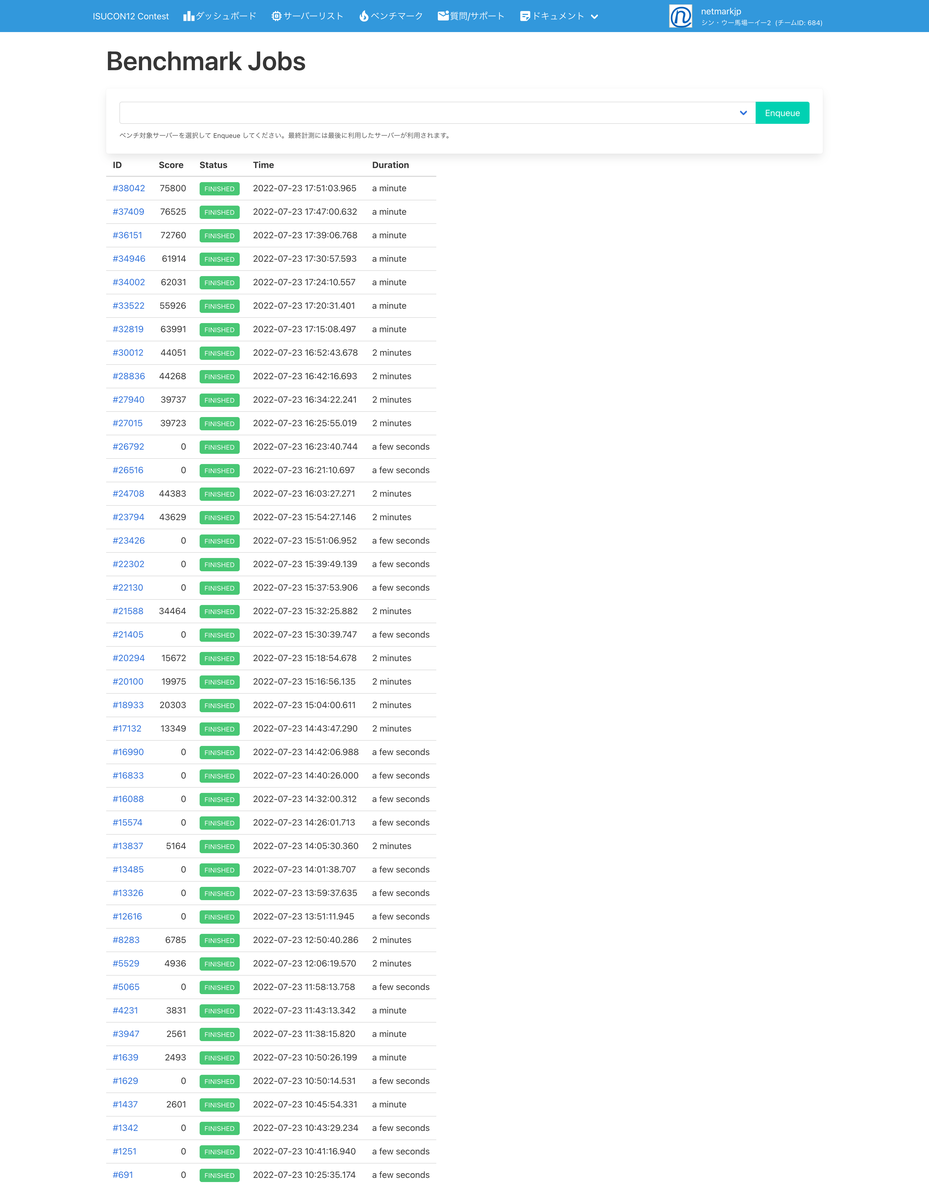
今回はベンチを回した回数は少なめになりました。
やったこと
時間 スコア 概要 でまとめていきます。
10:04 - 間違えてバージニア北部リージョンにCloudFormationスタック作成してしまう
開始早々やってしまいました。東京リージョンで作成すべきCloudFormationスタックをバージニア北部リージョンで作成してしまいました。運良く早い段階で気づいて作成完了する前に削除しています。
10:06 - 東京リージョンでCloudFormationスタックを再作成
バージニア北部で作成していることに気づいて東京リージョンで作り直しています。
10:11 - サーバにSSH接続、環境構築
3台のサーバが作成されたことを確認したのでSSHで接続、環境構築をしています。我々はサーバ上で直接編集するスタイルですのでサーバ上にnvimを用意しています。
nvimはAppImageで持ち込んでますが、今回 libfuse.so.2 がインストールされてなかったので --appimage-extract で展開しました。
nvim --appimage-extract rm nvim ln -s squashfs-root/AppRun nvim
10:25 0 Rustで初回ベンチ失敗
言語をRustに切り替えて初回ベンチを回しましたが0点でした。docker compose上はrunningになのに正常に応答できない原因を調べていたんですが、なんと5分近く経過してもcargo buildがまだ終わってなかったというオチ。まじかよ厳しいなRust。
繰り返しbuildすることを考えるとDocker環境では厳しいと判断してDockerを剥がす対処を行いました。*1
剥がして再ビルドを行なっている間にベンチ前準備スクリプト、ベンチ後解析スクリプト、解析用にログ出力などを整備しています。
10:45 2601 Rustでベンチ初成功
開始から45分経過してようやくベンチに成功しました。 ベンチ結果を解析するためのkataribe設定ファイルの整備などをこのタイミングで実施しています。
10:54 - 当日マニュアル読み合わせ
@ishikawa84g が整備してくれた当日マニュアルまとめ(プレゼン資料)の読み合わせをおこなっています。必要な情報だけを抽出してくれるのでとても助かっています。
11:22 - UUIDにあたりをつけるもcargo buildによってメモリ不足でサーバが固まりGoへの移行を決意
topコマンドでmysqldのCPU使用率が高いことを確認したのでMySQLのスロークエリーを確認、ユニークなキーを降り出す id_generator テーブルに対するクエリーが遅いことを確認しています。
当初AUTO_INCREMENTでいいのでは?と考えましたがテーブルまたぎでユニークなIDを割り振っていることが判明、しかし格納先の各テーブルのIDがVARCHAR(255)であることを確認したのでUUIDで格納する方針にしました。uuid crateを使って実装していたんですが…
ここで競技サーバ(メモリ4GB)上でnvim+rust-analyzerを開きながらcargo buildを実行したせいでメモリが枯渇、SSH操作ができなくなりました。ohまじか。メモリ足りない。厳しい。
なんとかAWS管理コンソールからサーバを再起動して復旧させたものの、このまま進めるのは難しいと判断してRust言語を諦め、Go言語への切り替えを決断しました。
11:38 2493 Goで初ベンチ
Go言語もDockerから剥がした上で初ベンチを実施しています。ようやくここが我々のスタートラインだ。
11:43 3831 UUID実装に切り替え
Rust実装の際に検討していたUUIDへの切り替えをこのタイミングで適用しました。スコアがちょっと伸びてます。
func dispenseID(ctx context.Context) (string, error) { return uuid.NewString(), nil }
12:06 4936 visit_historyをvisitに置き換え
まだmysqldのCPU負荷が高いのでMySQLのスロークエリーを確認したところ visit_history が最上位にきていることを確認。しかしSELECTしているのは1ヶ所しかなくUPDATEやDELETEもなし、また一番最初のレコードしか必要がないと判明したので、visit_historyへのINSERTをやめて別テーブルvisit を作って集計自体をやめる実装に切り替えることにしました。
CREATE TABLE visit ( `tenant_id` BIGINT UNSIGNED NOT NULL, `competition_id` VARCHAR(255) NOT NULL, `player_id` VARCHAR(255) NOT NULL, `created_at` BIGINT NOT NULL, PRIMARY KEY (tenant_id, competition_id, player_id) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8mb4;
初期データは流し込みinitializeで流し込み。
TRUNCATE TABLE visit; INSERT INTO visit (tenant_id, competition_id, player_id, created_at) SELECT tenant_id, competition_id, player_id, MIN(created_at) AS min_created_at FROM visit_history GROUP BY tenant_id, competition_id, player_id;
これが23秒近くクエリーだったのでちょっとヒヤヒヤものでしたが、あとで流し込みではなくdump/restore方式に置き換えています。
12:08 昼食タイム
昼食はしっかりとりましょう
12:50 6785 SQLiteにインデックス追加
前の対応でmysqldの負荷が大きく下がり、アプリ側の負荷になったことを確認しました。
ここでSQLiteのままでは厳しいのではないかと判断しMySQLへの移行を検討しています。webapp/sql/配下に移行で使えるsqlite3-to-sql スクリプトが存在し、これをそのまま使えるのではと検討。ですが、その前にまずはSQLiteにインデックスがなかったのでインデックスを追加しました。インデックスはMySQLに移行しても利用できますからね。
CREATE INDEX player_score_idx1 ON player_score (tenant_id, competition_id, player_id, row_num DESC); CREATE INDEX player_score_idx2 ON player_score (tenant_id, competition_id, row_num DESC); CREATE INDEX competition_idx1 ON competition (tenant_id, created_at DESC); CREATE INDEX player_idx1 ON player (tenant_id, created_at);
SQLiteの初期化にはinitial_data配下がコピー元になっていたのでinitial_data配下のdbファイルにインデックスを追加、また随時DBが追加されるのでwebapp/tenant/10_schema.sqlにも上記を盛り込んでいます。
14:05 5164 rankingのN+1を解消
インデックスを追加してisuportsプロセスの%CPUは下がったものの、sysとiowaitは下がらないことを確認。一旦まずはSQLの改善をできないかと考えてrankingの改善をを検討しています。まずranking内のN+1となっていた部分を解消させています。
N+1の解消はスコアが下がってしまったのですが、これは次の布石のため必要になると判断してそのまま続行しています。
14:43 13349 SQLiteのデータをMySQLに移行しつつ最終スコア記録用テーブルの作成
tenantDBの各テーブルにはtenant_idカラムが含まれておりきちんとデータが入っていたので、テーブルを分ける必要はないと判断して1つのテーブルにすべて集約することにしました。 webapp/sql/sqlite3-to-sqlを使って初期データの全テーブルをMySQLに流し込んでいます。
MySQLへのデータ流し込みに時間がかかることを想定し、
for f in initial_data/*.db ; do echo $f ; webapp/sql/sqlite3-to-sql $f | mysql -u isucon -pisucon isuports ; done
なお、この実行にとても時間がかかるのですが、redo logの無効化などをおこなって処理の軽量化をおこなっています。
/etc/apparmor.d/usr.sbin.mysqld
/dev/shm/ r, /dev/shm/** rwk,
/etc/mysql/mysql.conf.d/mysqld.cnf
# 本番環境でやってはいけない innodb_log_file_size = 64M innodb_doublewrite = 0 innodb_flush_log_at_trx_commit = 0 innodb_flush_log_at_timeout = 3 innodb_log_group_home_dir = /dev/shm
2022/07/31追記:7/27にリリースされたMySQL 8.0.30で、上記パラメータをそのまま適用はできなくなっています。お気をつけください。
-- 本番環境でやってはいけない ALTER INSTANCE DISABLE INNODB REDO_LOG;
ソースコードを注意深く読んだところ、必要なのはtenant, competition, playerごとに最終スコアだけだと判断できたので、それを記録するためのlast_player_scoreテーブルを作成しました。
CREATE TABLE last_player_score ( tenant_id BIGINT NOT NULL, player_id VARCHAR(255) NOT NULL, competition_id VARCHAR(255) NOT NULL, score BIGINT NOT NULL, row_num BIGINT NOT NULL, created_at BIGINT NOT NULL, updated_at BIGINT NOT NULL, INDEX last_player_score_idx1 (tenant_id, competition_id, score DESC, row_num ASC), PRIMARY KEY (tenant_id, player_id, competition_id) );
player_scoreにはすでにたくさんのレコードが登録されており、そこからlast_player_scoreを含めたデータの生成を毎回initializeでやっていると時間がいくらあっても足りないので、player, last_player_scoreはmysqldumpした結果をinitialize時に流し込むようにしています。
INSERT INTO last_player_score SELECT tenant_id, player_id, competition_id, score, row_num, created_at, updated_at FROM player_score WHERE (tenant_id, player_id, competition_id, row_num) IN (SELECT tenant_id, player_id, competition_id, MAX(row_num) FROM player_score GROUP BY tenant_id, player_id, competition_id);
mysqldump -u isucon -pisucon isuports player > ~/webapp/sql/admin/player.dump mysqldump -u isucon -pisucon isuports last_player_score > ~/webapp/sql/admin/last_player_score.dump
15:04 20303 インデックスの追加とinterpolateParamsを設定
SQLiteからMySQLに移行したのに合わせてボトルネックが再びMySQLになりはじめました。 MySQLのスロークエリーログを解析してインデックスを追加し、またPrepareが上位にきたのでGo実装の定番設定であるinterpolateParams=trueを追加しました。
ALTER TABLE player ADD INDEX (tenant_id, created_at DESC);
15:18 15672 competitionもMySQLへ移動してSQLite撤廃
まだSQLiteを利用していたcompetitionテーブルもMySQLへ移動させました。結果としてスコアは下がりましたが方向性は間違っていないはずと判断してそのまま突き進んでいます。
15:32 34464 参加者向けAPIのN+1を解消する
引き続き MySQLの%CPUが高いので、 GET /api/player/player/:player_id で呼ばれているcompetitionをベースとしたN+1をJOINすることで解消させています。
15:54 43629 flockを外してトランザクション実装に変更
SQLiteを使わない実装には切り替えていたものの、まだflockの削除は行っておらず、flockが原因と思われる余計な遅延をアクセスログの解析結果で確認していました。 そのためflockを外しつつ、問題が出ないようにトランザクション処理を実装しました。
16:03 44383 INSERT player後のSELECTを削除
playerへINSERTする際、INSERTした結果をSELECTする実装になっていましたが、INSERT時にID含め必要な情報はすべて揃っているため、SELECTを行わない実装に変更しました。
16:42 44268 last_player_scoreのデッドロック対策
捌ける量が増えてくるとlast_player_scoreのDELETEしてからINSERTする処理でデッドロックが発生していました。 この事象は今年のkayac社内ISUCONでも発生した事象で、「あ、これ進○ゼミでやったところだ!」となり以下のように変更しています。
- 変更前:レコードをDELETEしてからREPLACE
- 変更後:レコードをREPLACEしてから古いレコードをDELETE
16:52 44051 scoreのN+1を部分的に解消した
アクセスログを解析するとscoreが上位に来ていたので、N+1を可能な範囲で解消させました。スコアへの影響は微妙でしたがそのままとしています。
17:15 63991 サーバ分割(1台→2台構成)
まだ改善できる余地は見つけてはいたものの、残りの時間内ですぐに解消できそうになかったので、このタイミングでアプリとDBのサーバを分けることにしました。ここまでは1台で処理していました。
| サーバ | 変更前 | 変更後 |
|---|---|---|
| 1台目 | nginx + app(go) + MySQL | nginx + app(go) |
| 2台目 | 利用なし | MySQL |
| 3台目 | 利用なし | 利用なし |
我々のチームは基本的にサーバ分割はやることがなくなったり終盤になってから行うようにしています。その理由はボトルネックとなる箇所は随時変わるので、序盤に分割してもボトルネック次第で載せ替え直す必要がでてくる可能性があるためです。
17:24 62301 POST scoreで空データが投げられた場合に対処
空データが投げられてエラーになる状況が発生したので空でもエラーにならないよう対処しました。
17:39 72760 サーバ分割(2台構成→3台構成)
引き続きボトルネックはMySQLのように見えたのですが、ベンチの後半でapp側の負荷が上がるシーンが発生していることを確認したので、3台目にもappを設置しました。結果スコアがさらに伸びることを確認しています。
| サーバ | 変更前 | 変更後 |
|---|---|---|
| 1台目 | nginx + app(go) | nginx + app(go) |
| 2台目 | MySQL | MySQL |
| 3台目 | 利用なし | app(go) |
17:47 76525 再起動対応と各種ログ無効化
再起動時のapp-db間接続の問題を回避するため秘伝のタレである StartLimitBurst を/etc/systemd/system/isuports.serviceに投入しています。これぞインフラ屋らしい運用でカバー作戦だ。
[Service] StartLimitBurst=999
その他、各種ログの無効化を行いベストスコアは76525でした。再起動後に再度ベンチを行い75800が最終スコアとなっております。
*1:後から確認するとtargetやregistryはvolumesとしてマウントしてたのでdocker内でのcargo再ビルドは一応ケアされていた模様
書籍「達人が教えるWebパフォーマンスチューニング」はチューニングの考え方を教えてくれる良本
通称 #ISUCON本 を著者様からご恵贈いただきました。ありがとうございます。 gihyo.jp
所感
この書籍、言っていいのかわかりませんがまったくの初心者・初学者には難しい本かもしれません。私の感触では、Webサイトのプログラム作成、改修、構築、運用などに携わったり、Webサイトのパフォーマンスの問題に向き合ったことがある人が対象読者だと思いました。職種でいえばバックエンドエンジニア、インフラエンジニア、SREなどですね。もちろんそういった職種を目指している方や、純粋にISUCONに挑戦したい、パフォーマンスチューニングに興味がある、といった方も含まれます。
この本は特定の問題に対する直接的な答えではなく、パフォーマンスチューニングの考え方を教えてくれる内容になっています。この本を参考に実際に手を動かして実践するのが良いでしょう。現実のWebサイトをチューニングするでもいいですし、そのようなWebサイトが手元になければこの本でも何度も紹介されているprivate-isuやISUCON過去問にチャレンジするのが得策です。付録Aにprivate-isuの攻略実践がありますが、これをただ単になぞるだけでなく、さらにそこからチューニングを重ねていき手に馴染ませるのがいいと思います。
ISUCON12に向けて
今年もISUCONが開催されます。この書籍を参考に鍛錬を積んで、ISUCON本選で会いましょう。この書籍で参加者のレベルが底上げされてさらに熾烈な戦いになると思いますが、私も本選に出られるように頑張ります。 isucon.net
レビュー
私は本書籍のレビューには参加してなかったのですが、レビュアーの気持ちになっていくつか補足します。
Cahpter2 モニタリング
世の中には様々なモニタリングツールがありますが、ISUCONにおける我々のチームはtopとdstatがメインですね。ベンチマーク前からtmux上でtopコマンドとdstatをならべて起動しておき、ベンチマーク中の負荷状況はこの2つのコマンドの結果を観察しています。dstatの個人的オススメオプションは以下です。
dstat -tlamp
横幅が133文字になるのでターミナルの幅は広げておきましょう。
Chapter3 基礎的な負荷試験
P62 アクセスログの集計ツールとしてalpが紹介されていますが、拙作kataribeもご検討いただければ幸いです(宣伝)。 github.com ただ、kataribeは複雑になることを避けるため、あえてJSON形式のログには対応しませんでした。jqなどで整形してからkataribeに引き渡すか、書籍で紹介されているとおりalpの利用をご検討ください。
P68 アクセスログのローテーションについてですが、ISUCONにおいては昨年あたりからログの削除に truncate コマンドを使っています。
truncate -s 0 /var/log/nginx/access.log
truncateでファイルサイズを変更してもinodeは変わらずサービス再起動なども必要ないのでnginxの再起動やリロードも必要ありません。お試しください。truncateにdrawbackがあるようなら是非教えてください。
先日private-isuがarm64(aarch64)に対応したため、M1 Mac環境でもmultipass+cloud-initを利用することで手元で環境を用意できるようになりました。m1 macの手元で試したい方はこちらもご検討ください。
Chapter4 シナリオを持った負荷試験
P114 実際のアクセス状況を再現した負荷試験 についてですが、1つのWebページを読み込んだ際にどのようなリクエストが発生するかを調べる便利ツールが各種負荷テストツールには用意されています。
- k6 - Browser Recorder
- JMeter - Apache JMeter HTTP(S) Test Script Recorder
- Gatling - Recorder
- Tsung - Using the proxy recorder
こういったツールはリクエストヘッダーも採取できるほか、ajaxなども捕捉できるので便利です。
また、こういったツールが用意されていないベンチマークツールでも、ブラウザが生成するHAR(HTTP Archive)ファイルを使えば手動でシナリオを書くよりも比較的簡単にシナリオを構築できると思います。ぜひお試しください。 riotz.works
Chapter5 データベースのチューニング
pt-query-digestは私もISUCON中に愛用するツールです。pt-query-digestでよく使用するオプションは --limit 100% です。
Chapter7 キャッシュの活用
P193 Thundering herd problemについてですが、これは厳密にいえばCache Stampedeの方が用語として正しいかもしれません。深掘りする場合はThundering herd problemのほかに、Cache Stampedeでも調べてみることをオススメします。
Chapter9 OSの基礎知識とチューニング
P252 systemdのunitファイルにulimit設定を追加するにあたり /etc/systemd/system/mysql.service.d/limits.conf を手動で作成されていますが、これは以下のコマンドを使うのがオススメです。
systemctl edit mysql.service
$EDITOR に設定されたエディタが起動するので上記limits.confで追加した記述を記載すればokです。 systemctl editで設定する場合は、手動でのdaemon-reloadも不要ですので、そのままrestartを実行することができます。
ISUCON11本選でチーム ウー馬場ーイー2 として参加し、7位になりました
TL;DR
運営の皆様、参加者の皆様、本当にありがとうございました。ISUCONと嫁は私の生きがいです。 優勝までは届きませんでしたが、Failで終わったISUCON10本選から少し人権を取り戻した気がします。
スコアについて
本選時間中のベストスコアは80,473、再計測による最終スコアは83,756、7位でした。 本来は12位ぐらいので実力でしたがFailとなったチームがいたので運良く10位以内に入れたようです。

今回、途中で急激なスコアの伸びたことが理由でTVer賞をいただいたのですが、スコアが伸びたのは開始から3時間44分後の1台構成から2台構成に切り替えたタイミングでした。最初しばらくは1台構成で進めて、煮詰まったら複数台構成としているので、予め複数台構成にするよりも大きく伸びやすいというのがあると思います。そのようなスコア評価があることは事前に知らなかったのでラッキーでしたね。わいわい。
体制
| あいこん | なまえ | やくわり |
|---|---|---|
| |
matsuu | バリバリ実装する前衛 |
| |
netmarkjp | 司令塔 |
| |
ishikawa84g | |
予選と同様に3人別々リモート、VDO.ninjaで画面共有、Discordで音声+文字チャットです。
使用したツールなど
- sshrc ssh接続先に手元の環境(dotfilesなど)を持っていく
- tmux ターミナル分割として
- vim 我らがエディタ
- top リソース使用状況確認
- iotop I/Oが多いプロセス特定 NEW!
- dstat リソース使用状況確認
- MySQLTuner MySQLパラメータ確認
- kataribe アクセスログ解析
- pt-query-digest MySQLスロークエリー解析
このチームはサーバにSSH接続してサーバ上で直接vimを叩いてプログラムを変更するポリシーなので、isuconユーザ上にお互いのvim環境やtmuxの設定を分離するためにsshrcを使っています。便利。
最終構成
今回は最後までDBの負荷が高い状態を改善できませんでした。トランザクション処理を考えるとDBレプリケーションで整合性をとりつつ性能を出すのは難しいと判断したのでDB1台、app2台としています。
| サーバ | 構成要素 | 備考 |
|---|---|---|
| 1台目 | nginx + app(go) | |
| 2台目 | app(go) | |
| 3台目 | mysql |
やったこと
10:16 31,928 初期スコア
一通り環境を揃えてperformance_schemaなども有効化してベンチマークを回した結果です。
10:35 36,321 interpolateParams=true
golangの王道、interpolateParams=trueを設定しています。
10:41 32,810 スロークエリーログ集計に変更
performance_schemaからの集計は見にくいとの結論から従来どおりpt-query-digestによるスロークエリーログ集計に切り替えました。スコアは落ちました。
11:24 30,448 トランザクション処理引き剥がし
スロークエリーログで上位にCOMMITがきてしまい内容がわからないため、外せるトランザクション処理は引き剥がしていきました。スコアは下がりましたがスロークエリーログの見通しは良くなったためそのまま進めます。
11:30 33,240 アプリログ外しとCOMMIT特定
11:24の対応でもある程度COMMITは排除できたのですが、残るCOMMITを判別するため、COMMITにコメントを入れることでスロークエリーログの出力を分ける対策をしました。こんな感じ。
- if err = tx.Commit(); err != nil { + if _, err := tx.Exec("COMMIT /* RegisterCourses */"); err != nil {
これは慧眼。自分たちを褒めてやりたい。スコアが少し上がったのはアプリログ外しのおかげです。
11:51 40,492 mysqlとnginxのパラメータチューニング
秘伝のタレの時間です。
/etc/mysql/mysql.conf.d/mysqld.cnf
innodb_log_file_size = 32M innodb_doublewrite = 0 innodb_flush_log_at_trx_commit = 0 innodb_flush_log_at_timeout = 3 innodb_log_group_home_dir = /dev/shm disable-log-bin
innodb_log_group_home_dir の変更はそのままだと正しく動作しないためAppArmorも調整してます。ワレワレハAppArmorト共存スル。
nginxはupstreamとHTTP/1.1の接続設定の他、nginxのerror.logに client request body is buffered to a temporary file が出力されていたのでassignmentsは proxy_request_buffering off を追加しています。
location ~ ^/api/courses/.*/classes/.*/assignments$ {
proxy_pass http://app;
proxy_set_header Connection "";
proxy_http_version 1.1;
proxy_request_buffering off;
}
12:06 39,072 db接続数を増やしたら遅くなった
DBの接続数がデフォルトの10のままだったので100に増やしてみました。
- db.SetMaxOpenConns(10) + db.SetMaxOpenConns(100) + db.SetMaxIdleConns(100)
が、これが元でスコアが下がりました。状況を確認するとFOR UPDATEによるロック待ちで滞留が増えてしまっているようでした。なるほどなるほど。ただ将来ロックを解消して接続数を増やす必要がでてくるだろうと判断して差し戻さずそのまま進めています。
12:52 41,368 cpをlnに変更する
今回の本選は提出された課題(pdfファイル)をzip形式で一括ダウンロードする機能があるのですが、pdfファイルをzipで圧縮する前にcpでファイル名をかえつつ集めている処理があったのですが、ここでインフラエンジニア力が発揮されcpをlnで置き換える奇策が適用されました。
// ファイル名を指定の形式に変更
for _, submission := range submissions {
if err := exec.Command(
- "cp",
+ "ln",
AssignmentsDirectory+classID+"-"+submission.UserID+".pdf",
tmpDir+submission.UserCode+"-"+submission.FileName,
).Run(); err != nil {
lnコマンドは-sをつければシンボリックリンクを作成しますが、-sをつけなければハードリンクになるため副作用が発生しにくいうえに高速にリンクを作成できるため今回の用途にピッタリでした。わいわい。これがインフラエンジニアだ。
13:35 42,491 GetGradesのN+1を一部解消
/api/users/me/grades でたびたびタイムアウトが発生しており、IFNULLが使われれているクエリーがスロークエリーログのトップに来ていたのですが、かんたんな改善が思いつかず、取り急ぎ同処理内の修正できそうなN+1を解消しています。スコアの伸びはわずかです。
13:44 68,795 2台構成に変更
ここまでで一番のボトルネック(と思っていた)DBに対して打つ手がなくなってきたので、3台目をDBサーバとして利用するよう構成変更を行いました。このときのスコアの伸びがTVer賞になっています。
16:07 75163 GPAの統計値を予め計算したスコアテーブルを作成
DBサーバを分離してもDBのCPU負荷がボトルネックになっていたため、採点をするたびに total_score として積算していくためのカラムを追加したのですがdeadlockが多発、ええいテーブルも分離して積算だとテーブルを分けてもdeadlock、最終的には一応スコアが出るようになったのですが、何がなんだかさっぱりわからずやたら時間を食ってしまいました。厳しい。
16:22 77,029 課題提出周りを改善
zipダウンロードでnginxにてbufferingが発生していることを確認したため proxy_buffering off を追加しています。
location ~ ^/api/courses/.*/classes/.*/assignments/export$ {
proxy_pass http://app;
proxy_set_header Connection "";
proxy_http_version 1.1;
proxy_buffering off;
}
また、合わせてアップロードされた課題は io.ReadAll() の代わりに io.Copy() でメモリに読ませず直接出力するようにしています。
16:45 73,395 DB接続数上限を200に増やすもスコア下がる
DBの接続数が上限まで使い切っていたので上限を増やしてみたものの、スコアはむしろ下がってしまいました。LOCK待ちが増えたからですね。
17:00 78,336 appを2台構成に
引き続きDBのCPU負荷がボトルネックになっている状況(だと思っていた)のですがDBを2台構成にするのは難しい(と思い込んでいた)ので2台目にもappを配置して最終構成としました。結果、スコアは少しだけ伸びました。
17:35 80,473 ログ出力を無効にしてスコアアップ
nginxのアクセスログとmysqlのスロークエリーログの出力を停止することで若干のスコアアップとなりました。
18:00まで 偏差値がマイナスになっていることに気づいて慌てふためく
ふとサイトにログインして動作確認していたところ、S99999ユーザで偏差値がマイナス値になっていることに気づいて焦りました。
 学内GPA偏差値 -331.8 とは
学内GPA偏差値 -331.8 とは
偏差値でマイナスとかありえへんのでどこかでエンバグしてしまったのだと思い、関連しそうな場所をrevertしてみたりしたものの改善せず。ええい仕方ない最終的にスコアのよかった実装にしてそのままフィニッシュとなりました。
#isucon 7位だったらしい。まじか。S99999ユーザの偏差値がマイナスであることが終了直前で発覚し、慌てふためいたもののそのままフィニッシュしたんだが大丈夫だったのか(フラグ
— matsuu (ウー馬場ーイー2) (@matsuu) 2021年9月19日
この偏差値は最初からバグってたのか、エンバグしたのかはまだわかってません。追試で調査を行おうと思います。おわり。
おまけ1 やったこと公開しました。
予選本選でやったことはgithubで公開してます。
おまけ2 OODAループについて
本選直前のgihyo.jpのインタビュー記事でも少しだけ回答したのですが、我々の戦略はOODAループを基本としています。
OODAループは、観察(Observe)- 情勢への適応(Orient)- 意思決定(Decide)- 行動(Act)- ループ(Implicit Guidance & Control, Feedforward / Feedback Loop)によって、健全な意思決定を実現するというものであり、理論の名称は、これらの頭文字から命名されている。
これはgihyo.jpのインタビュー記事の設問に
1.今回の予選課題が発表されて,最初に感じたこと,また,具体的に取り組むに当たってどのような方針でスタートしましたか。
とあって、事前に環境整備の準備はするものの、予選課題の発表後に大方針のようなもの決めてないしPDCAじゃないよなぁ、とググってたら見つけた理論で、我らが今までISUCONでやっていたことはOODAループと同じだった、というだけです。
OODAループに関する書籍やYouTube解説動画などもあるのですが、ビジネス寄りでちょっと胡散臭い雰囲気があるのが残念ですね。エンジニアの我々は理論だけ活用していきましょう。
OODAループに関して1冊だけ書籍購入しました。まだ全部読めてません。
